
- DR Jeong,B Lee,I Shin,Y Kwon
- 2023 IEEE Symposium on Security and Privacy (SP)
INTRODUCTION
以往的工作
Razzer 和 Snowboard 使用启发式方法,结合了静态分析和动态分析但不考虑覆盖率,这会导致它们无法消除产生相同覆盖的执行冗余;KRACE 提出了别名覆盖法来追踪两条并行的指令,但无法有效地总结并发错误的行为,而且它是随机地调度指令而没有将之前探索过的考虑进去
本文的工作
- 定义一种新的度量线程交错的指标:交错段覆盖(Interleaving segment coverage),以求能够反映出常见并发漏洞的性质
- 用这种度量来驱动搜索和变异
实验结果
- 在最新的 Linux kernel 中发现了 21 个并发漏洞,而且这些漏洞此前其他 fuzzer 都没能检测出来
- 在检测已知漏洞方面比以往的 fuzzer 平均快 4.1 倍
BACKGROUND
- 传统的覆盖率引导:对并发漏洞无能为力
- Razzer 和 Snowboard:选一对指令并确定它们的执行顺序
- KRACE:交错覆盖率引导,随机调度
- Conzzer:交错覆盖率引导,覆盖 kernel 的调度程序,指定两个函数并发执行,并控制线程调度
MOTIVATION
情景:A2->B1->A4 时会触发并发漏洞
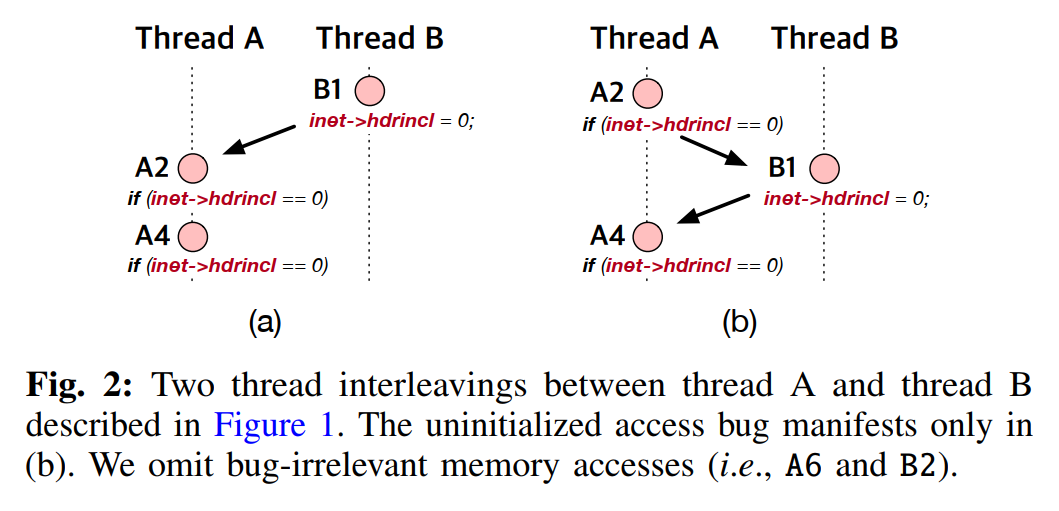
- 如果交错覆盖度量在 B1->A2->A4 时就结束搜索,fuzzer 将错过这个漏洞
- 如果这样的指令有上千条,搜索空间过大会导致效率过低;所以需要在两者之间寻求一个平衡点
- 如果按 B1->A2->A4 顺序执行从而尚未发现漏洞,但它们由于访问的都是同一片内存,我们需要从度量中得到可能存在漏洞的反馈
EXPORING THREAD INTERLEAVING SPACE
步骤:
- 将以探索出的交错分解为包含少量指令的片段
- 利用这些片段变异生成未探索过的交错
- 将变异后的片段重新组合成整体,并确定后面的调度方式
Segmentizing thread interleaving
此前有一份调查指出:绝大多数并发漏洞都是由至多四次共享内存访问造成的,多出来的内存访问其实不会造成实质性的影响。所以将交错段的大小限制到最多四条访存指令既能方便度量覆盖率,又能保持漏洞检测的能力
举例:如下图
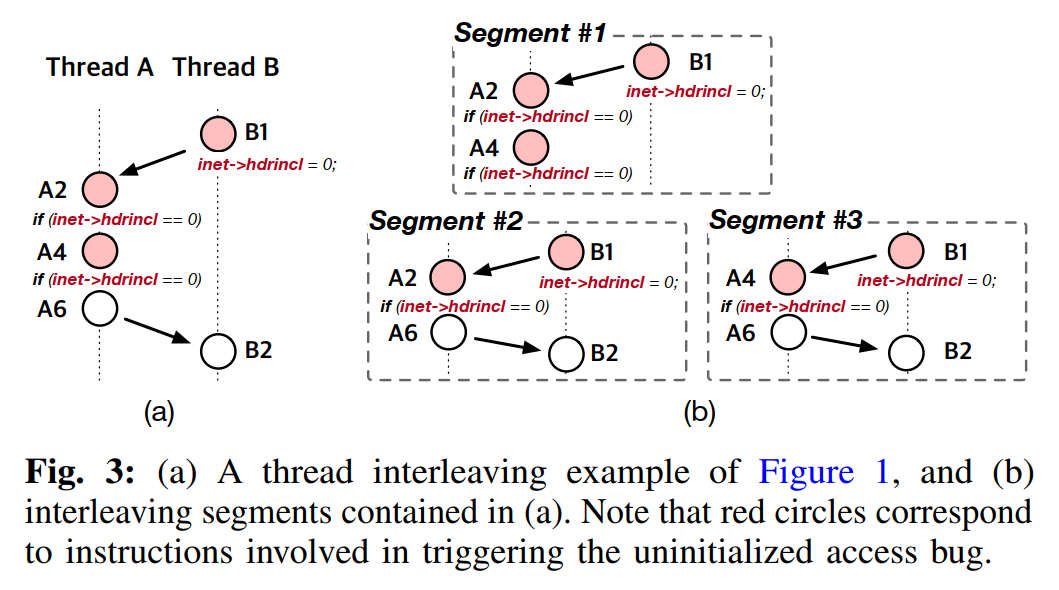
Interleaving Segment Coverage
本文将已探索出的线程交错表示成一个有向无环图(DAG),然后用 DAG 的子图(称为段图)代表一个交错段,如下图
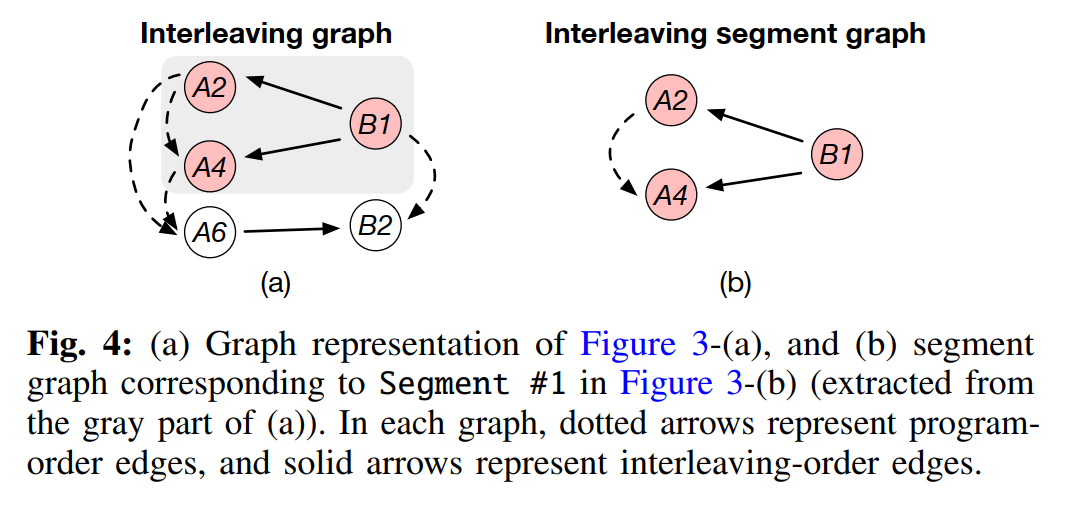
在 DAG 中,一个节点代表一条访存指令,边代表指令间的执行顺序,而其中又分为单线程的顺序边(program-order edge,虚线)和并发的交错边(interleaving-order edge,实线),而交错边的判定条件是:1)访问同一片内存、2)至少一个写操作、3)不同线程
要想生成段图,首先先生成 DAG(这里不详细写了),然后选两条交错边以及它们连接的顶点,然后提取连接这些点的所有边就可以生成一个段图,最终得到一个段图集合
本文提出的交错段覆盖就是跟踪上面生成的段图。如果在多线程下不断发现新的段图,则说明 fuzzer 需要投入更多算力进去,而如果没有新的段图假如集合则说明这里已经不再值得探索。当然,这样做还是会消耗不少内存,所以本文用可以反应边的方向的默克尔散列表(好像就是默克尔树?)来存储段图
Mutation-based Interleaving Exporation
fuzzer 会将已探索出的交错段变异成包含新的交错的未探索的交错段,然后将变异的交错段组合成一个可能的线程交错并生成一个线程调度点
这里所谓的变异其实就是翻转一条交错边来改变执行顺序,翻转得来的段图必须是全新的无环图
Recomposing mutated segment graphs
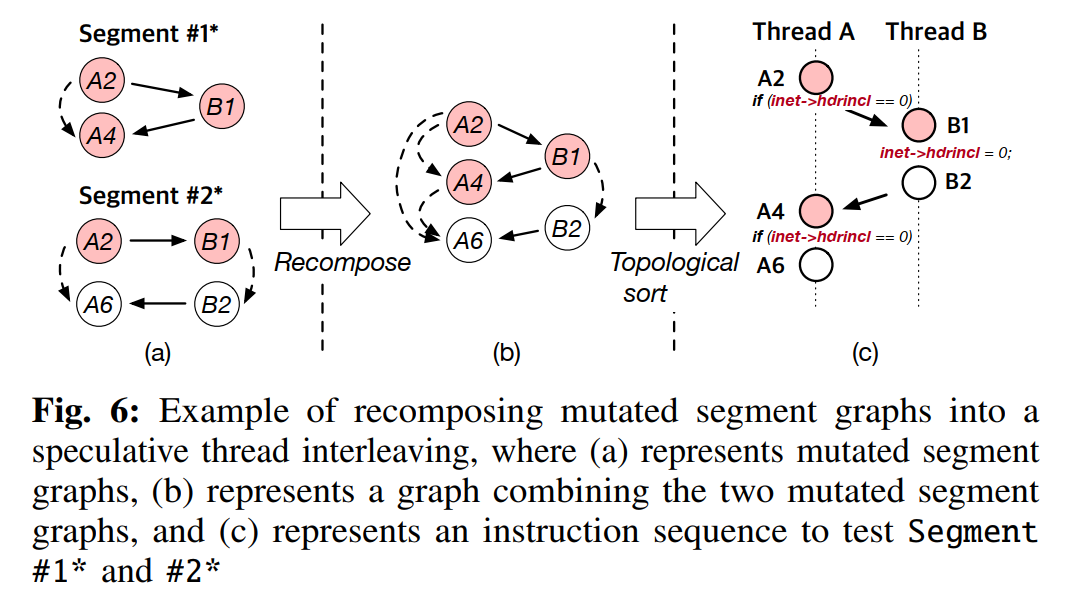
在下一步的搜索中会选择其中的一个变异段图,但如果变异段图集合很大就需要多次搜索迭代,所以可以选择将多个突变段图重组成一个大一些的段图来一次性测试多个变异
重组生成的段图依然必须是一个无环图,做法是将小段图逐个加入大段图检查是否有环,然后得到无环图子集
Recomposing mutated segment graphs
上步获得无环图子集后,fuzzer 就会创建一个调度点,每个调度点会描述应要发生抢占的指令和每个系统调用的结束以及下一个要执行的线程,fuzzer 对无环图子集使用拓扑排序来生成调度点,如前面那张图的 (c) 部分,A2、B2、A6就是调度点
DESIGN OF SEGFUZZ
SEGFUZZ 有两个 fuzzing 阶段,也是基于 syzkaller 实现的。第一阶段是单线程,此阶段使用分支覆盖引导来搜索执行路径;第二阶段是多线程,此阶段使用交错段覆盖引导。两个阶段都会跟踪每个系统调用访存的时间戳
单线程阶段就是用 syzlang 生成系统调用序列,这里应该跟 syzkaller 区别不大。结束后会将得到的单线程序列和探索出的分支覆盖传递给下一阶段
多线程阶段会将两个单线程序列转变成一组多线程序列,然后变异并生成调度点。在执行的时候执行器会依赖各种 bug 检测器来监测
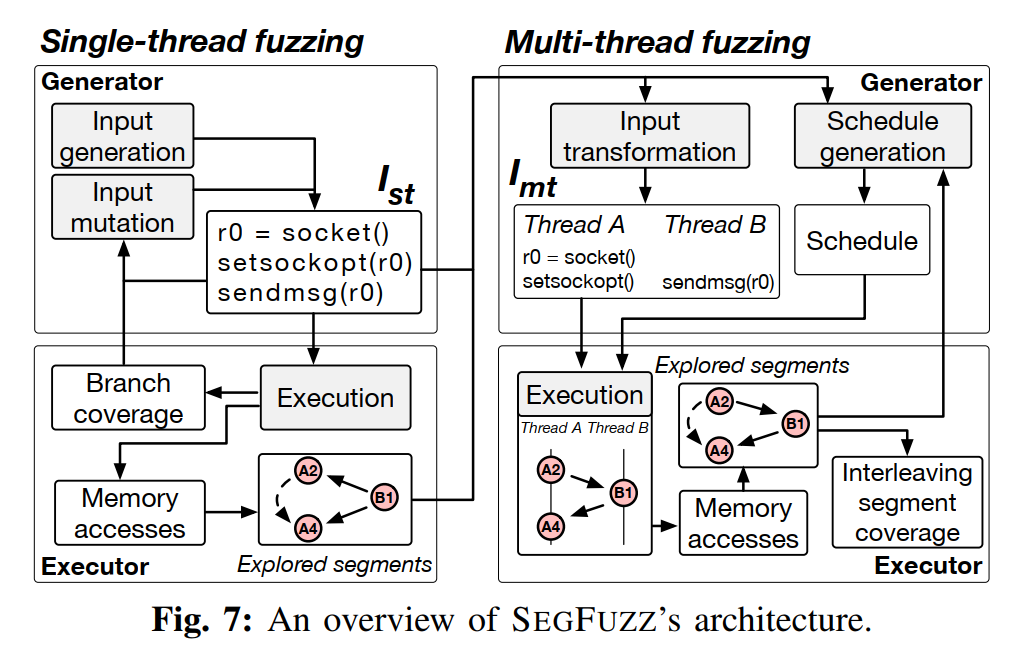
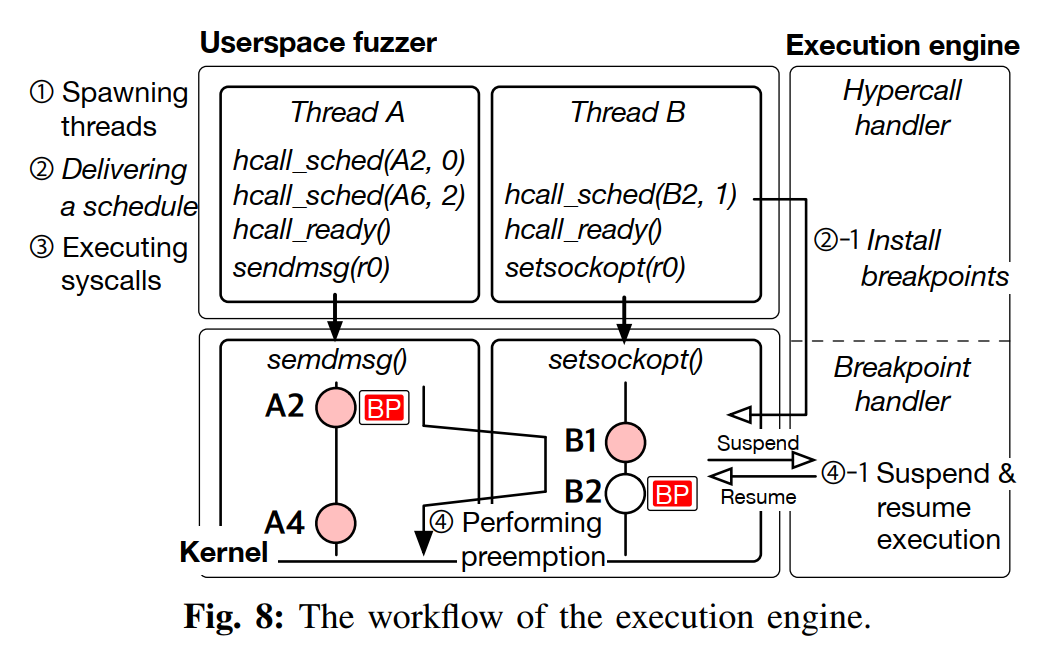
对于跟踪系统调用,SEGFUZZ 会在每个基本块的入口插桩一个回调函数,其会记录:访存地址、指令地址、访存的大小和类型以及时间戳。插桩是利用 LLVM 实现的
对于线程调度,执行器会在执行系统调用前通过后门接口发送调度点,然后执行引擎会在调度点用 Intel CPU 自带的功能下硬断,运行到断点时就暂停当前线程并切换。如果在这个过程中发生了内核本身的线程切换就选择遵循内核调度带来的影响
EVALUTION
主要是相对于此前一些方法尤其是 KRACE 的性能对比,这里按下不表
DISCUSSION
- 虽然超过九成并发漏洞是由少于四个交错段触发的,但仍有小部分漏洞牵涉的交错段更多
- 缺乏能以较高效率跟踪内核后台并发线程的手段

Comments NOTHING