
建议使用浅色背景阅读
准备工作
使用环境
服务器:
DELL PowerEdge R740
2 CPUs @ 3.10GHz, 40 cores with 512GB of memory
操作系统:
Red Hat Enterprise Linux 7.9
使用工具
Candence Virtuoso IC618
Synopsys Design Compiler
Candence Innovus 15.2
设计流程
设计指标及完成情况
设计任务
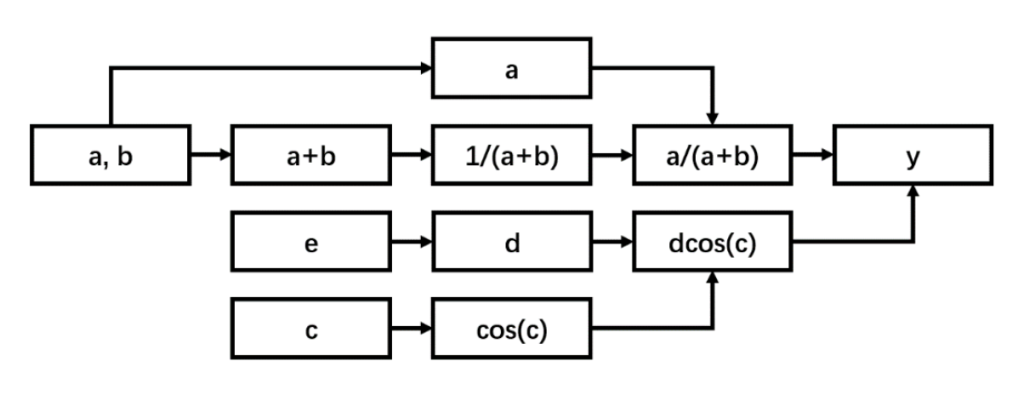
设计一电路模块,实现函数
其中,
| 信号 | 类型 |
|---|---|
| clk | 250MHz时钟信号 |
| a | 11位无符号整数 |
| b | 11位无符号整数 |
| c | 11位无符号整数 |
| d | 10位无符号整数 |
| e | 1位(异步输入) |
| y | 12位有符号数(二进制补码) |
要求
输入端口有且仅有 a[10:0],b[10:0],c[10:0],e,clk,输出端口为 y[11:0];
y 的误差范围为±1/211
时钟 clk 频率为 250MHz,且 clock jitter 为 200ps, a,b,c 的数据变化速率与 clk 同步,d[9:0]作为可编程系数通过异步输入端口 e 写入(只写一次);
e 同步于另一时钟 clkb,与 clk 异步,Tclkb=3ns;
在满足条件的情况下,优化 latency;
在满足条件的情况下,优化功耗。
指标完成情况概述
Verilog 仿真、前仿真、门极仿真、后仿真中,在测试条件下 y 值均正确输出,因此达到设计指标。
测试时,在 392ns 输入信号,在 426ns 时输出结果,由于工作周期内时钟第一个上升沿在 394ns,因此认为模块的处理时间为 32.0264ns,即 4 个时钟周期。
功耗为 63.0833 mW。
经过测试,LVS 和 DRC 均通过。
由于在除法器设计中使用了查找表格式,面积与功耗均较表现良好,且满足要求时序。
核心模块Verilog设计
指标分析及方案预设
将
代码编写
(a+b) 计算
通过要输入 a[10:0]、b[10:0]来计算出 (a+b) 的值。经过验算,为防止溢出,将输出设置为 12 位。
xxxxxxxxxxalways @(posedge clk) begin if (rst) begin reg_a_plus_b_stage_0 < 0; end else begin reg_a_plus_b_stage_0 < reg_a reg_b; endend
1/(a+b) 计算
将上文计算出的 (a+b) 通过查除法表的形式得到1/(a+b),经过验算,为防止溢出与保证精度,将输出设置为 21 位。
xxxxxxxxxxdiv div_inst( .aplusb (reg_a_plus_b_stage_0), .div_result (wire_div_result));
always @(posedge clk) begin if (rst) begin reg_div_result < 0; end else begin reg_div_result < wire_div_result; endend
可以看作是将0~
xxxxxxxxxxcos cos_inst( .c (reg_c), .cos_result (wire_cos_result));
always @(posedge clk) begin if (rst) begin reg_cos_result < 0; end else begin reg_cos_result < wire_cos_result; endend
d异步输入
指标要求 d[9:0] 必须由 e[0:0] 以串行异步输入的形式载入数据,并且 e 参考 Tclk2 为 3ns, d 参考 Tclk 为 4ns,同步器依赖 e 的上升沿进行触发(因此第一位数需要为 1),以 clk 上升沿 为触发将 e 从后往前存入 delay [2:0] 中,再以 delay 的最高位上升沿为触发,将此时的 e 按位 累加到 d[9:0] 中,实现两个时钟系统的衔接。
testbench端,信号异步输入:
xxxxxxxxxx`define data_0 10'b1110000000`define data_1 10'b1111110000
initial begin #16; repeat(10)begin d_bit < (d[9]) `data_1 : `data_0; d < d << 1; repeat(10)@(posedge clk2)begin e < d_bit[9]; d_bit < d_bit << 1; end end #200;end
function端,信号接收与处理:
xxxxxxxxxxmodule asyn ( input wire clk, input wire [0:0] e, output reg [9:0] d); reg [2:0] delay;
always @(posedge clk) delay < {delay[1:0],e};
always @(posedge delay[2]) d < {d[8:0],e};endmodule
乘法计算
乘法的原理为移位相加,这里为了保证乘法运算中的延迟能符合 250MHz 要求,将每个乘数均拆分为 3 小段,单独相乘、积相加,以此来降低高位数乘法的运算时延。下列示例代码就将乘数 reg_div_result[20:0] 均分为 3 段,将乘数 reg_a_stage_1[10:0]拆分为两 段。彼此两两相乘后对齐相加,得到积 tol_div_a[31:0]。
xxxxxxxxxxreg sign_stage_2;reg [12:0] temp_ah0, temp_ah1, temp_ah2; //将积的高 39 位拆分成 ah0,ah1,ah2 三段进行计算reg [11:0] temp_al0, temp_al1, temp_al2; //将积的低 36 位拆分成 al0,al1,al2 三段进行计算reg [10:0] temp_dh0, temp_dh1; //将积的高 11 位拆分成 dh0,dh1 两段进行计算reg [11:0] temp_dl0, temp_dl1; //将积的低 12 位拆分成 dl0,dl1 两段进行计算
reg sign_stage_3;reg [31:0] tol_div_a;reg [22:0] tol_cos_d;
always @(posedge clk) begin//第一级流水线 if (rst) begin sign_stage_2 < 0; //初始化 temp_ah0 < 0; temp_ah1 < 0; temp_ah2 < 0; temp_al0 < 0; temp_al1 < 0; temp_al2 < 0; end else begin sign_stage_2 < reg_cos_result_stage_1[12];//符号位隔离
//计算 a 乘以 1/(a+b) temp_ah0 < reg_a_stage_1[10:5] reg_div_result[20:14]; temp_ah1 < reg_a_stage_1[10:5] reg_div_result[13:7]; temp_ah2 < reg_a_stage_1[10:5] reg_div_result[6:0];
temp_al0 < reg_a_stage_1[4:0] reg_div_result[20:14]; temp_al1 < reg_a_stage_1[4:0] reg_div_result[13:7]; temp_al2 < reg_a_stage_1[4:0] reg_div_result[6:0];
//计算 d 乘以 cos temp_dh0 < reg_cos_result_stage_1_tem[12:7] reg_d[9:5]; temp_dh1 < reg_cos_result_stage_1_tem[12:7] reg_d[4:0];
temp_dl0 < reg_cos_result_stage_1_tem[6:0] reg_d[9:5]; temp_dl1 < reg_cos_result_stage_1_tem[6:0] reg_d[4:0]; endend
always @(posedge clk) begin//第二级流水线 if (rst) begin sign_stage_3 < 0; //初始化 tol_div_a < 0; tol_cos_d < 0; end else begin sign_stage_3 < sign_stage_2; tol_div_a < {temp_ah0, 19'b0} {temp_ah1, 12'b0} {temp_ah2, 5'b0} {temp_al0, 14'b0} {temp_al1, 7'b0} temp_al2; tol_cos_d < {temp_dh0, 12'b0} {temp_dh1, 7'b0 } {temp_dl0, 5'b0} temp_dl1; endend
Testbench
xxxxxxxxxx`timescale 1ns10ps`define data_0 10'b1110000000`define data_1 10'b1111110000
module tb_function_gen ( a,b,c,e,clk,rst);
output reg clk; output reg clk2; output reg [10:0] a; output reg [10:0] b; output reg [10:0] c; output reg [0:0] e 0; output reg [0:0] rst;
reg [9:0] d 11'd870; //11'd1023 reg [9:0] d_bit; wire[11:0] y;
initial begin #5 clk 1'b0; #5 clk2 1'b0; #20 rst 1; //reset #5 rst 0; end
initial begin //异步信号d输入 #16; repeat(10)begin d_bit < (d[9]) `data_1 : `data_0; d < d << 1; repeat(10)@(posedge clk2)begin e < d_bit[9]; d_bit < d_bit << 1; end end #200;end
initial begin a < 0; //初始化 b < 0; c < 0; clk < 0; clk2 < 0;
#42 rst 1; //reset信号 #50 rst 0;
#300 a < 11'd1145; //a数据输入 1145 b < 11'd0928; //b数据输入 928 c < 11'd2009; //c数据输入 2009 end
always #2 clk < clk;//时钟信号always #1.5 clk2 < clk2;
function_gen function_gen_inst( .clk (clk ), .rst (rst ), .a (a), .b (b), .c (c), .e (e), .y (y));
endmodule
RTL行为仿真
Cadence AMS配置
Design Compiler综合
综合优化脚本
时序约束分析
功耗与面积分析
门级网表仿真
Cadence AMS配置
Innovus自动布局布线
版图综合脚本
时钟树综合与优化
一些时序debug手段
Calibre版图验证
LVS与修正
DRC与修正
版图综合后仿真
时序检查与分析

Comments 3 条评论
单机贴吧?
打个胶先
