
- Shan Lu,Soyeon Park,Eunsoo Seo,Yuanyuan Zhou
- 2008 ASPLOS XIII
之前看 SEGFUZZ 发现了这篇 08 年的高引,SEGFUZZ 变异策略的依据就源于这篇论文,虽然年代比较老但依旧很有价值
- 为了打字方便,bug 统一翻译成漏洞了
- 文章里的“当前”等字眼是指文章的年代而非现在
- 参考:[论文翻译] 从错误中学习 - 对工程中的并发bug的特性的综合性研究 - 知乎
Introduction
多核 CPU 的普及让并发编程变得越来越流行,但并发编程的思维方式其实是反直觉的,这让习惯于顺序思考方式的程序员的编码变得很困难;而且并发漏洞的出现必然有一定的不确定性,所以连调试和复现漏洞都不容易
此前的工作都提出了一些有效的漏洞检测方法,但仍有一些问题尚未解决
对于并发漏洞检测方面:
- 现有的工具是否能检测所有的并发漏洞?有没有尚未能解决的并发漏洞类型?工具对于漏洞的假设是否是否会造成遗漏?
- 这些工具对诊断和修复漏洞有多大帮助?通过直接加锁就能解决的漏洞占比多少?程序员修复并发漏洞又需要哪些信息?
对于并发程序的测试和模型检测:
- 遍历所有的线程交错是不现实的,那么是否可以有选择地遍历部分交错顺序而依旧有效暴露出大部分的漏洞?
- 并发漏洞通常涉及多少个线程、多少个变量、多少次内存访问?
模型检测(Model Checking)是一种用于验证程序是否满足某个性质的方法,具体来说是:给定一个程序和一个用时序逻辑描述的性质,将程序建模并转化成一个自动机,然后将性质逻辑取反得到另一个自动机,最后将这两个自动机求交看是不是空集,是则说明程序违反这个性质
模型检测的优点是速度相对于以前的方法更快,缺点则是难以解决超多状态的大型程序和状态爆炸,所以常常用 soundness 的方式去建模自动机
07 年的图灵奖就颁给了在模型检测方面做出开创性贡献的三位大佬:Edmund M. Clarke、E. Allen Emerson 和 Joseph Sifakis
更多介绍可以参看
并发编程语言设计方面
- 事务内存(Transaction Memory,TM)可以避免哪些类型的漏洞?
- TM 的设计需要关注哪些问题?
- 除了 TM 还有哪些语言设计对并发编程有利?
事务内存(Transaction Memory,TM,也有人叫事务性内存)是一种用于无锁编程的方法,用于解决并发编程的开发效率和程序性能之间的矛盾,其源于数据库中事务的概念,可以由软件、硬件或软硬件混合实现
事务内存具有原子性、一致性、隔离性:原子性表明事务不可分;一致性表明任何事务在访问共享内存前后系统的状态是一致的;隔离性则表明未提交的事务操作不会影响系统的状态
本文认为研究并发漏洞本身以及程序员编写并发程序时的常见错误有利于揭示如何更好地避免并发漏洞(正应题目“Learning from Mistakes”),于是收集研究了来自 MySQL、Apache、Mozilla 和 OpenOffice 的 105 个并发漏洞(包括 74 个非死锁漏洞和 31 个死锁漏洞),最终写就这篇优秀的 survey
论文开篇将成果整理为一张表格,分别对应 Section 3、Section 4 和 Section 5,后续将使用 Finding n 来指代些发现和启示
| 漏洞模式中的发现 | 启示 |
|---|---|
| 几乎所有(93%)的非死锁并发漏洞都属于两种简单的错误范式:atomicity-violation(违背原子性)和 order-violation(违背顺序) | 并发漏洞检测只要聚焦于这两种漏洞模式就可以发现绝大多数并发漏洞 |
| 大约三分之一(32%)的非死锁漏洞都是 order-violation,而且目前的研究都不能很好地解决这些漏洞 | 需要新的检测方法去定位 order-violation,现有的 atomicity-violation 和数据竞争检测策略都不能定位order-violation |
| 漏洞复现中的发现 | 启示 |
|---|---|
| 几乎所有(96%)的并发漏洞都可以通过两个线程的偏序执行来复现 | 两个线程的并发就可以暴露大多数漏洞 |
| 一些(22%)死锁漏洞是由单个线程等待获取自己持有的资源所引发的 | 单线程死锁检测和测试技术可以减少简单的死锁漏洞 |
| 许多(66%)的非死锁并发漏洞只涉及对一个变量的并发操作 | 聚焦于单变量的并发操作可以简化并发漏洞检测 |
| 三分之一(34%)的非死锁并发漏洞涉及对多个变量的并发操作 | 需要新的检测方式去定位多变量并发漏洞 |
| 几乎所有(97%)的死锁漏洞只涉及最多两个线程循环等待最多两个资源 | 聚焦于两个线程对两个资源的获取和释放就可以暴露绝大多数死锁漏洞 |
| 几乎所有(92%)的并发漏洞可以在至多四次内存操作中以某种偏序执行和复现 | 可以以组为单位进行并发测试,每组只需要包含很少的指令就可以暴露大多数并发漏洞 |
| 修复策略中的发现 | 启示 |
|---|---|
| 四分之三(73%)的非死锁漏洞是通过其他策略修复的,而非添加或修改锁 | 漏洞检测工具需要更多信息来帮助程序员修复并发漏洞 |
| 许多(61%)的死锁漏洞是通过锁等技术禁止一个线程获取一个资源来修复的,但这样往往会引入非死锁漏洞 | 修复死锁漏洞可能会引入非死锁漏洞,程序员需要特别的信息来帮助修复死锁漏洞 |
| 漏洞预防中的发现 | 启示 |
|---|---|
| 事务内存可以避免大约三分之一(39%)的并发漏洞 | 事务内存似乎很有前途 |
| 如果可以解决现有的一些问题或困扰,事务内存可以避免超过三分之一(42%)的并发漏洞 | 事务内存的设计者应该想办法解决这些问题和困扰 |
| 一些(19%)并发漏洞由于其独有的模式,事务内存无法提供解决方案 | C/C++ 设计者需要引入一些新的语言特性来表达“顺序”这一语义 |
Methodology
团队找了 MySQL、Apache、Mozilla 和 OpenOffice 四个典型的开源应用,它们的特点是主要使用 C/C++ 编写、体量大、漏洞库维护良好、分别代表不同场景的服务端应用和客户端应用且使用并发实现不同的目的
漏洞则是用 race,dead-lock,synchronization,concurrency,lock,mutex,atomic,compete 等关键词及其变体搜索了数千份漏洞报告并随机筛选了 500 份,最终挑选出 105 个描述清晰、报告完整且有修复方案的漏洞。文章主要研究死锁漏洞和非死锁并发漏洞两种漏洞模式,前者 31 个、后者 74 个

文章还给出了一些名词及其定义,这里就不一个个翻译了,直接上图
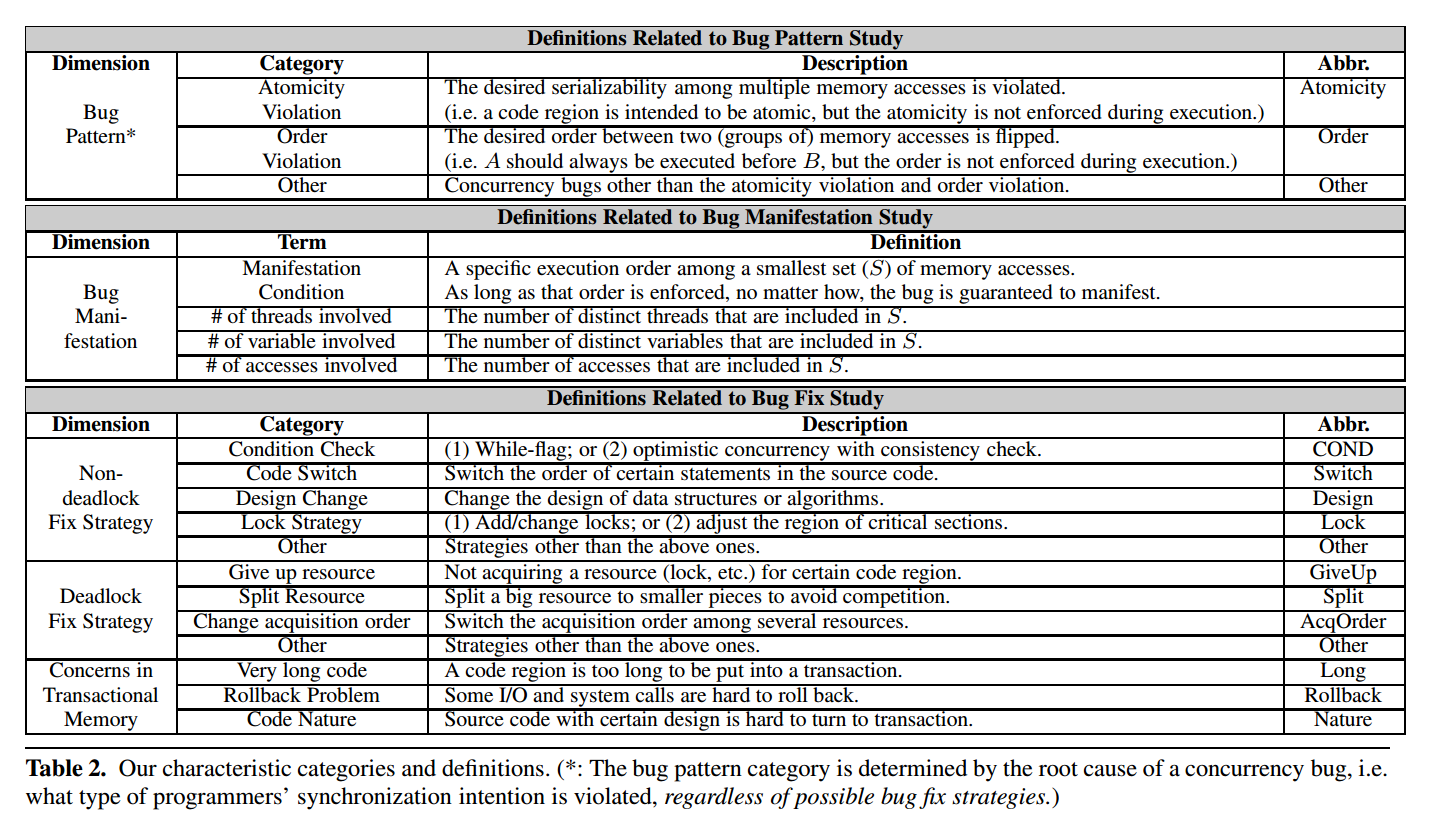
其中比较重要的几个名词
- 违背原子性(atomicity-violation):指某些操作并非像程序员所预期的一般是原子化执行的
- 违背顺序(order-violation):程序的执行顺序并非程序员所预期的顺序
- 复现条件(manifestation-condition):一组某种顺序的内存操作指令,只要按这种顺序执行就能复现漏洞
总结起来文章将研究以下几点
- 漏洞模式:文章将漏洞分为三仲模式:违背原子性、违背顺序和其他,数据竞争更多表现为一种中性行为,所以这里并未将其归类为一种漏洞模式
- 复现条件:文章将研究并发漏洞复现所需的条件
- 修复策略:文章将研究漏洞的最终解决方案以及修复过程中出现的错误解决方案
Bug pattern study
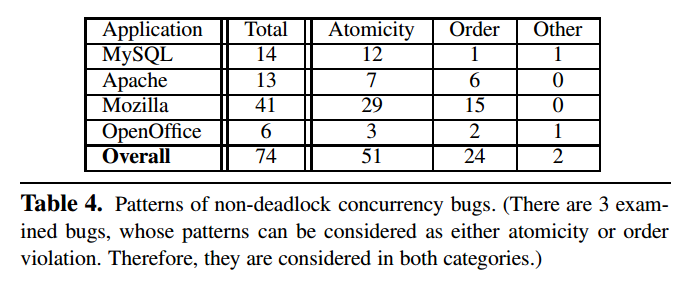
Finding 1
- 几乎所有(93%)的非死锁并发漏洞都属于两种简单的错误范式:atomicity-violation(违背原子性)和 order-violation(违背顺序)
- 并发漏洞检测只要聚焦于这两种漏洞模式就可以发现绝大多数并发漏洞

程序员常常使用顺序的思考方式,所以他们倾向于假设某些小的代码区域是原子的,如上图,若假设 S1 和 S2 之间是原子的,在并发期间如果两者之间执行了 S3 将会导致程序崩溃

另外,程序员也常常假设两个操作间的执行顺序而忘记强制指定执行顺序,如上图,线程 2 由线程 1 创建,因此常被认为线程 1 初始化mThread会先于线程 2 的引用,然而若线程 2 执行得很快就会在初始化前就引用mThread导致崩溃。值得一提的是,尽管加锁可以解决这个漏洞,但这属于违背顺序而非违背原子性

还有一些其他类型的漏洞模式,不过比较少见,如上图,monitor 线程通过使用计时器来检测死锁,但如果线程很多导致循环很慢,monitor 将认为出现死锁导致崩溃
Finding 2
- 大约三分之一(32%)的非死锁漏洞都是 order-violation,而且目前的研究都不能很好地解决这些漏洞
- 需要新的检测方法去定位 order-violation,现有的 atomicity-violation 和数据竞争检测策略都不能定位order-violation
除了之前的初始化前引用的写-读顺序错误以外,还有写-写顺序错误和两个线程对多个变量读写的顺序错误

如上图的 while-flag,在原本的预期中,S2 先设置 flag,然后在 S3 循环中等待 S4 执行完毕;然而若 S4 速度很快先于 S2 执行,那么线程 1 就会陷入死循环
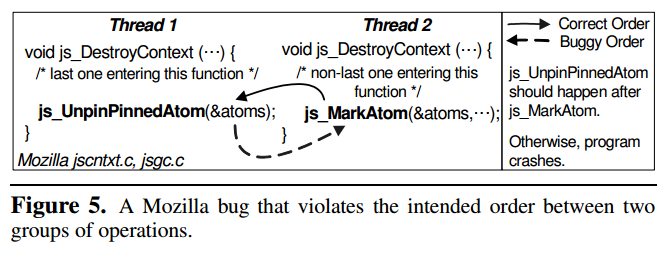
如上图,js_UnpinPinnedAtom会释放atoms中所有的元素,js_MarkAtom会将元素放入到atoms中;预期顺序下程序希望最后一个线程执行js_UnpinPinnedAtom,然而如果最后两个线程几乎同时结束导致先执行了js_UnpinPinnedAtom就有可能导致非预期行为
现有的并发漏洞检测器更多聚焦于竞争漏洞和违背原子性漏洞,而很少关注违背顺序漏洞
Bug manifestation study
漏洞涉及多少个线程?
Finding 3
- 几乎所有(96%)的并发漏洞都可以通过两个线程的偏序执行来复现
- 两个线程的并发就可以暴露大多数漏洞
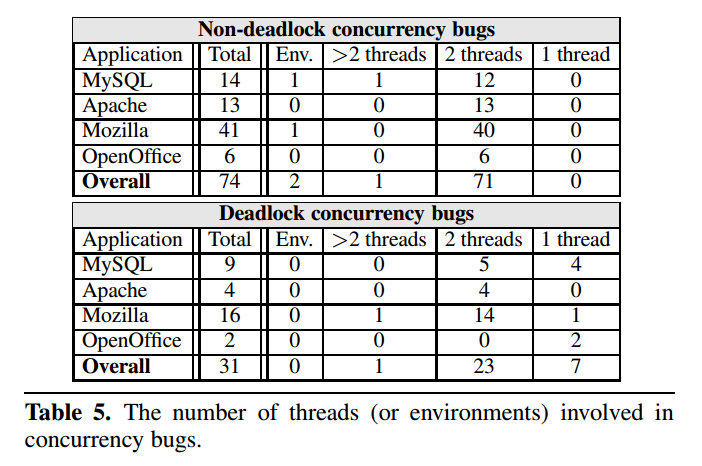
这个 finding 通过上面的表格就很显而易见了,绝大多数并发漏洞都只关乎两个线程,只不过它们在高负载情况下更容易暴露出来
Finding 4
- 一些(22%)死锁漏洞是由单个线程等待获取自己持有的资源所引发的
- 单线程死锁检测和测试技术可以减少简单的死锁漏洞
这种漏洞通常在一个线程试图获取自身持有的资源时发生,检测时不需要考虑外部环境,检测难度相对来说较低
漏洞涉及多少个变量?
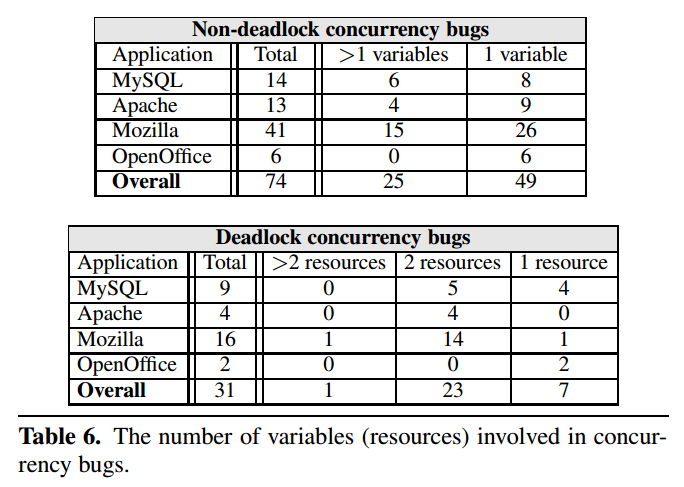
Finding 5
- 许多(66%)的非死锁并发漏洞只涉及对一个变量的并发操作
- 聚焦于单变量的并发操作可以简化并发漏洞检测
这个 finding 证实了我们的直觉:可以通过以特定顺序操作一个变量来复现并发漏洞,这个发现证明了许多基于单变量假设的检测器的有效性(如聚焦于一个变量的访问同步性或一个变量相关的原子区域)
Finding 6
- 三分之一(34%)的非死锁并发漏洞涉及对多个变量的并发操作
- 需要新的检测方式去定位多变量并发漏洞
变量之间通常有语义上的关联性,当不同的代码操作这些相关的变量导致程序状态不一致时,就会出现多变量漏洞
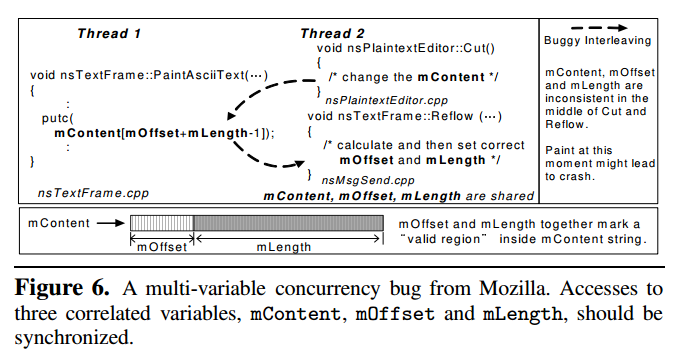
如上图,mOffset和mLength共同描述了mContent的范围,线程 1 和线程 2 对这三个变量操作应该是同步的,而仅仅控制其中一个变量的同步操作并不能解决问题
目前大部分漏洞检测工具都只关注单变量并发漏洞,但是可见多变量并发漏洞也不容忽视。多变量并发漏洞的检测难度在于难以判断变量之间同步关系的联系性
Finding 7
- 几乎所有(97%)的死锁漏洞只涉及最多两个线程循环等待最多两个资源
- 聚焦于两个线程对两个资源的获取和释放就可以暴露绝大多数死锁漏洞
死锁漏洞中只有一个是由三个线程循环等待资源产生的,所以可以聚焦于对资源和线程成对测试来有效减少测试的复杂度
漏洞涉及多少次内存操作?
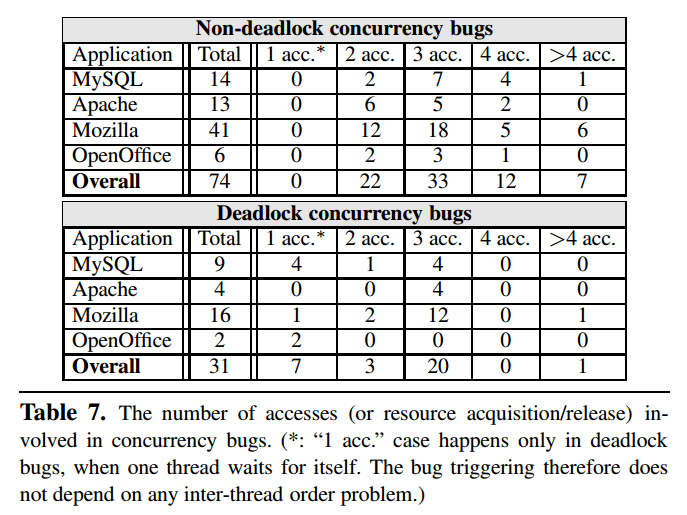
Finding 8
- 几乎所有(92%)的并发漏洞可以在至多四次内存操作中以某种偏序执行和复现
- 90% 的非死锁漏洞可以通过至多四次内存操作复现
- 97% 的死锁漏洞可以通过至多四次内存操作复现
- 可以以组为单位进行并发测试,每组只需要包含很少的指令就可以暴露大多数并发漏洞
结合前面的 finding,其实不难发现这个 finding 是自然的,因为大多数并发漏洞都只涉及两个线程或两个变量
这个 finding 十分有用,通过它可以将指数复杂度转化成多项式复杂度,大大简化了测试的难度
Bug fix study
修复策略

Finding 9
- 四分之三(73%)的非死锁漏洞是通过其他策略修复的,而非添加或修改锁
- 漏洞检测工具需要更多信息来帮助程序员修复并发漏洞
这个 finding 是反直觉的,因为我们常常就使用加锁来解决并发 bug,但事实却恰恰相反
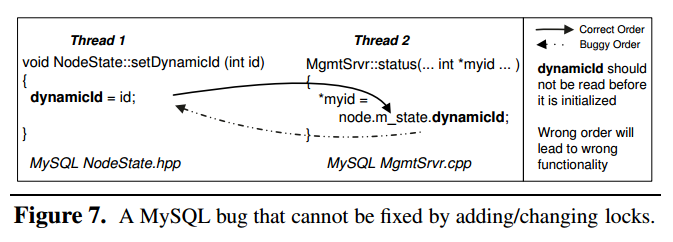
如上图,简单地加锁就无法解决这个问题
简单地加锁往往会引入其他新的问题,且锁的使用也会带来性能问题。下面给出一些其他的修复策略
- 条件检测(Condition check,COND):一种方法是前面提到的 while-flag 形式,另一种是用一个 if 来做一致性检查,不过后者在很多情形下其实是治标不治本
- 代码转换(Code switch,Switch):调整代码的执行顺序来规避违背顺序漏洞
- 改变算法/数据结构设计(Design)
可见并发漏洞的修复很复杂,所以需要检测工具给出更多的信息来帮助程序员识别并发漏洞的模式等
Finding 10
- 许多(61%)的死锁漏洞是通过锁等技术禁止一个线程获取一个资源来修复的,但这样往往会引入新的非死锁漏洞
- 修复死锁漏洞可能会引入非死锁漏洞,程序员需要特别的信息来帮助修复死锁漏洞
程序员发现在许多情况下没必要加锁,因此他们往往会选择放弃加锁以避免死锁。尽管这种策略可能会引入非死锁并发漏洞,程序员也倾向于相信发生概率很小。
未来,由乐观并发和回滚重新执行相结合的技术(比如TM)可以帮助修复一些死锁bug,但是他们也可能会带来活锁问题
修复过程中的错误
在 57 个 Mozilla 并发漏洞中,有 17 个漏洞至少有一次错误的补丁;而在 23 个布丁中,有 6 个仅是降低了 bug 发生的概率而未能根治问题,5 个引入了新的并发 bug,12 个引入了新的非并发 bug
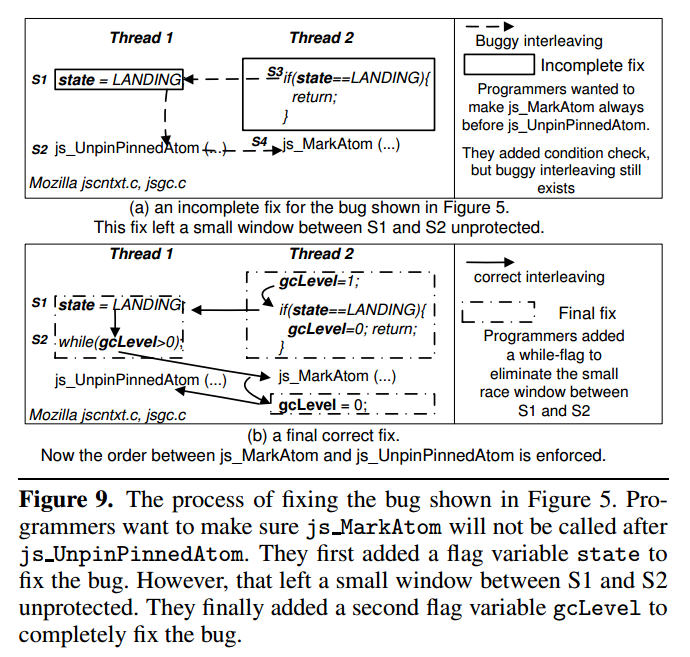
contributor:我太难了
如何避免漏洞?
一个好的编程语言应该简化并发编程的难度,TM 就是一个很好的方向,不过 TM 并非我关注的方向,所以这里只做简略描述
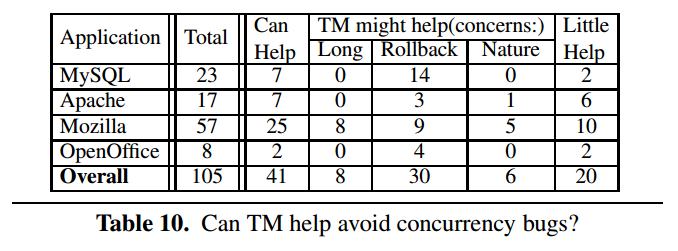
如上表可见,TM 可以十分有效地避免很多并发漏洞
Finding 11
- 事务内存可以避免大约三分之一(39%)的并发漏洞
- 事务内存似乎很有前途
关键代码区域相对较小、简单的违背原子性漏洞和死锁漏洞可以在使用 TM 中获得很大的受益,TM 的事务性可以非常有效地解决这些问题
Finding 12
- 如果可以解决现有的一些问题或困扰,事务内存可以避免超过三分之一(42%)的并发漏洞
- 事务内存的设计者应该想办法解决这些问题和困扰
尚未得到妥善解决的问题主要在于 I/O 操作、原子区域的大小以及一些特殊性质的代码等,TM 实际上可以解决这些问题,但性能开销无法忽视
Finding 13
- 一些(19%)并发漏洞由于其独有的模式,事务内存无法提供解决方案
- C/C++ 设计者需要引入一些新的语言特性来表达“顺序”这一语义
这需要语言和 TM 加强语义上的设计来帮助程序员更好地描述他们的预期执行顺序
Other characteristic
漏洞影响:105 个漏洞中 34 个会导致崩溃、37 个会导致程序挂起,所以并发漏洞带来的可靠性问题还是很大的
难以复现:某些漏洞甚至只在某台机器上可以复现(可能跟硬件平台有关),非常玄乎
测试用例:Mozilla 一度关闭了错误报告板块,因为这些报告往往无法复现漏洞,很多情况下维护者只能通过猜漏洞来提交补丁
诊断工具:很少工具能很有效地帮助程序员调试并发漏洞,GDB 都往往无能为力;反观内存相关的漏洞则有丰富的工具来帮助诊断和调试

Comments NOTHING